
Ecco come installare OCRFeeder, l’utile software per effettuare scansioni OCR di immagini, documenti ecc con Linux.

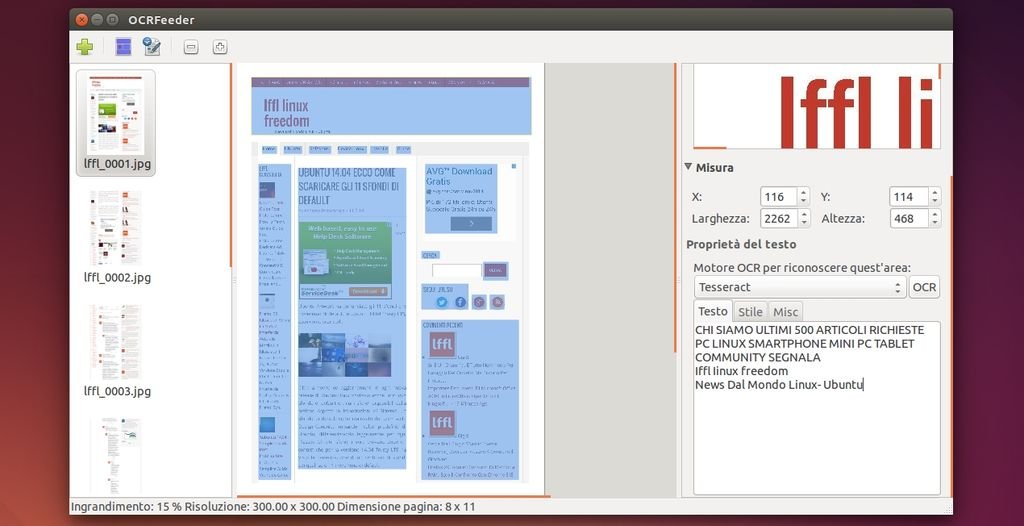
OCRFeeder è un progetto open source, sviluppato dai developer GNOME; che punta a fornire una semplice ed intuitiva interfaccia grafica di Tesseract ed altri motori di riconoscimento ottico dei caratteri (OCR). Attraverso OCRFeeder potremo operare in immagini in documenti testuali consentendoci di ottenere ottimi risultati anche in lingua italiana, con la possibilità di poter editare il testo estratto in LibreOffice, OpenOffice, AbiWord ecc. Con OCRFeeder potremo potremo effettuare la scansione di una o più immagini di diversi formati tra i quali jpeg, png ricorrendo al comando Aggiungi Cartella è possibile specificare un’intera directory alla quale importare tutte le immagini, documenti PDF ecc. Una volta integrate le le immagini o documenti basta selezionare una parte ti testo o l’intera immagine e cliccare sul pulsante OCR per iniziare la scansione.
Semplice e funzionale OCRFeeder è disponibile nei repository ufficiali delle principali distribuzioni Linux, di default però installa la versione inglese di tesseract-ocr, per questo motivo oltre all’applicazione andremo ad installare anche il software riconoscimento ottico dei caratteri specifico per la lingua italiana.
Per installare OCRFeeder in Ubuntu, Debian e derivate (compreso Linux Mint ed elementary OS) basta digitare:
sudo apt-get install ocrfeeder tesseract-ocr-ita
Per installare OCRFeeder in Arch Linux e derivate:
sudo pacman -Sy ocrfeeder tesseract tesseract-data-ita
Per installare OCRFeeder in Fedora basta scaricare i pacchetti rpm da questa pagina e installare Tesseract nella versione italiana digitando:
sudo yum install tesseract-langpack-ita
Al termine dell’installazione basta avviare OCRFeeder da menu, prima di effettuare la scansione verifichiamo di aver correttamente impostato tesseract nella lingua italiana dalle preferenze dell’applicazione.
