
Vi presentiamo Linux-Intelligent-Ocr-Solution ottimo software dedicato al riconoscimento ottico dei caratteri per Linux, ecco come installarlo.

Di recente abbiamo presentato diversi software dedicati al riconoscimento ottimo dei caratteri (OCR) in grado quindi di estrarre testo da immagini, documenti ecc con estrema facilità. Tra i software OCR disponibili per Linux troviamo anche Lios (Linux-Intelligent-Ocr-Solution) progetto open source dalle caratteristiche davvero molto interessanti.
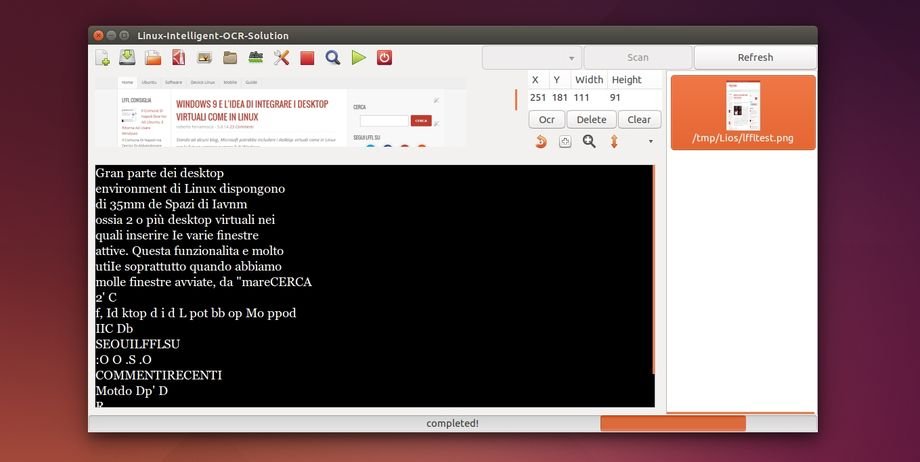
Linux-Intelligent-Ocr-Solution è un software, scritto in Python 3, in grado di acquisire immagini da uno scanner o webcam (supporto ancora in fase di sviluppo) oppure da un documento PDF ed elaborarle attraverso Cuneiform o Tesseract.
Linux-Intelligent-Ocr-Solution è un software, scritto in Python 3, in grado di acquisire immagini da uno scanner o webcam (supporto ancora in fase di sviluppo) oppure da un documento PDF ed elaborarle attraverso Cuneiform o Tesseract.
Grazie ad una semplice interfaccia grafica possiamo effettuare la scansione dell’intera immagine / documento oppure solo una parte di essa, dispone anche di correttore automatico (attraverso aspell) per correggere il testo scansionato.
Da notare inoltre numerose opzioni riguardanti l’acquisizione attraverso lo scanner, Linux-Intelligent-Ocr-Solution ci consente inoltre di stampare direttamente il testo estratto oppure esportare il tutto in un documento PDF, dalle preferenze è disponibile anche il supporto per visualizzazione ottimizzata per utenti ipovedenti. 
Da notare inoltre numerose opzioni riguardanti l’acquisizione attraverso lo scanner, Linux-Intelligent-Ocr-Solution ci consente inoltre di stampare direttamente il testo estratto oppure esportare il tutto in un documento PDF, dalle preferenze è disponibile anche il supporto per visualizzazione ottimizzata per utenti ipovedenti.

– Installare Linux-Intelligent-Ocr-Solution
Linux-Intelligent-Ocr-Solution viene rilasciato per Ubuntu, Debian, Fedora, openSUSE, ecc grazie ai pacchetti deb e rpm disponibili in questa pagina.
Una volta installato dalle preferenze possiamo decidere se utilizzare Cuneiform oppure Tesseract.
In caso che scegliamo Tesseract dovremo installare il supporto per la lingua italiana, digitando ad esempio per Debian, Ubuntu e derivate:
sudo apt-get install tesseract-ocr-ita
Se dobbiamo effettuare la scansione OCR di libri antichi in italiano consiglio di installare il pacchetto tesseract-ocr-ita-old digitando da terminale:
sudo apt-get install tesseract-ocr-ita-old
una volta installato possiamo impostare la lingua italiana in Tesseract.
