Linux: come ricavare il testo dalle immagini con TextSnatcher
Se siete alla ricerca di un metodo immediato per copiare il testo dalle immagini su Linux dovete assolutamente provare TextSnatcher. L’app è disponibile da un paio di settimane su Flathub e funziona davvero bene.
Diciamolo subito, le funzionalità di estrazione di testo da foto, pdf e simili non sono certamente da catalogare alla voce ‘novità’. Esistono diversi tool efficaci per questa operazione, anche da riga di comando. Ciò che colpisce di TextSnatcher è la semplicità d’uso, il suo vero valore aggiunto.
TextSnatcher
Se spostassimo lo sguardo su altri sistemi operativi, mi riferisco a macOS o Android, scopriremmo che i programmi OCR (riconoscimento ottico dei caratteri) vengono integrati nativamente nelle funzioni di visualizzazione delle immagini. Per questo sarebbe comprensibile attendersi la stessa cosa anche sulle distro GNU/Linux.
Avere un’app come TextSnatcher a bordo potrebbe tornare utile. L’app esegue il riconoscimento ottico dei caratteri in pochi secondi, consentendovi di copiare rapidamente il testo da qualsiasi cosa sia visibile sul vostro schermo negli appunti di sistema, pronto per essere incollato altrove. TextSnatcher nasce per essere usato su elementaryOS ma funziona perfettamente anche su altri sistemi operativi. Alla base del tool troviamo il motore open source OCR Tesseract, che lavora alla perfezione con immagini ad alta risoluzione.
How-to
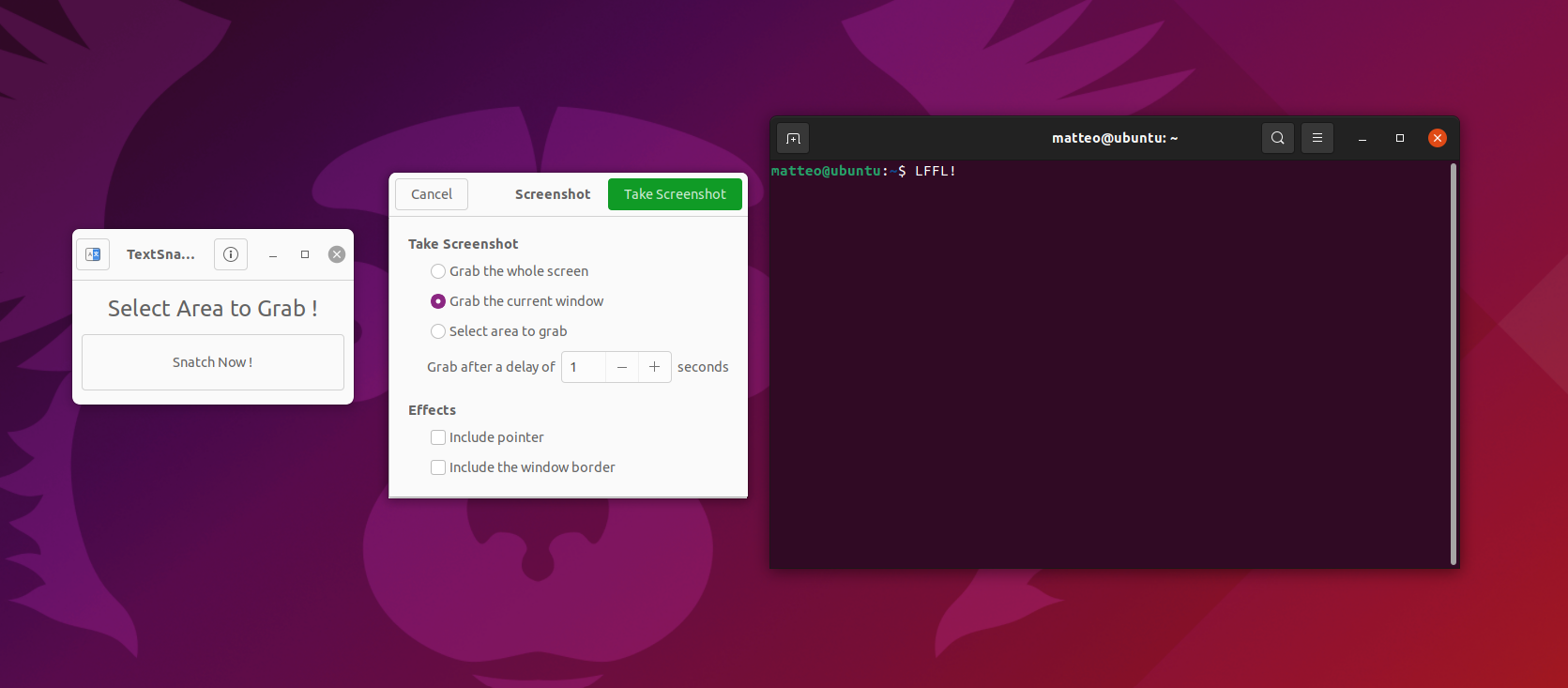
Il funzionamento è immediato. Basta aprire l’app, fare clic sul pulsante “Snatch Now!” e scegliere una delle tre opzioni a disposizione:
- Scannerizzare l’intero schermo
- Scannerizzare la finestra attiva
- Selezionare solo una porzione di schermo da scannerizzare
Quest’ultima opzione è la migliore, permette di effettuare uno screenshot della sola porzione di testo che vi interessa copiare. Per testare il buon funzionamento sono partito da un’immagine molto semplice, con il logo di Ubuntu.
Ovviamente l’app ha scannerizzato perfettamente l’immagine. Sono quindi passato a un interessantissimo (😏) PDF dell’Agenzia delle Entrate. Anche in questo caso il tool è stato perfetto, vedere per credere:
Chiaramente su immagini a bassa risoluzione fa più fatica e la traduzione può dare luogo a risultati incomprensibili, poiché lo strumento tenta di assegnare caratteri di testo a frammenti casuali di bordi, immagini, ecc.
Ad esempio con questa immagine il risultato che l’app restituisce è erroneamente “130, 00”, ma l’errore è concesso visto lo stato dell’immagine.
Provatelo e fatemi sapere come vi trovate!
Seguiteci sul nostro canale Telegram, sulla nostra pagina Facebook e su Google News. Nel campo qui sotto è possibile commentare e creare spunti di discussione inerenti le tematiche trattate sul blog.