

Ecco la seconda parte della mini-guida introduttiva a ZFS per sysadmin. Concluderò prima il discorso sulla struttura del file system e sulle cache. Continuando poi il discorso fatto ieri sul COW, vi mostrerò come effettuare uno snapshot, poiché si tratta di una funzionalità nativa di ZFS. Come per la prima parte, anche qui lascerò qualche link esterno, per evitare di dilungarmi in spiegazioni di argomenti troppo generici.
Sysadmin GNU/Linux & ZFS: concetti generali – parte 2
Originariamente sviluppato da Sun, lo sviluppo di ZFS è in seguito passato al progetto OpenZFS. Gli obbiettivi perseguiti, sono, schematizzando, i seguenti:
- Integrità dei dati: tutti i dati includono un checksum, Quando un dato è scritto, il checksum è calcolato e scritto a sua volta. Quando il dato è riletto in un momento successivo, il checksum è nuovamente calcolato. In caso di errore ZFS proverà a correggerlo automaticamente, se è disponibile una ridondanza del dato;
- Pooled storage;
- Performance: utilizzando un meccanismo complesso di cache.
Come esportare ed importare uno storage pool
ZFS facilita la vita dei sysadmin, semplificando la migrazione delle unità tra sistemi. Permette, infatti, di esportare il pool di archiviazione, in modo da poter smontare le unità di archiviazione, scollegare i cavi e spostare le unità su un altro server, ad esempio. Una volta sul nuovo sistema, ZFS dà la possibilità di importare il pool di archiviazione, indipendentemente dall’ordine delle unità. Vediamo la procedura da seguire:
- Esportare lo storage pool;
zpool export miopool
- Importare lo storage pool sul nuovo server;
zpool import tank
- Verificare se la procedura è andata a buon fine.
zpool status miopool
state: ONLINEDataset
Un dataset è simile ad uno standard file system montato. Di default, il file system viene montato in /miopool. Creiamo, ad esempio, un dataset “prova”. Assegniamogli, poi, una quota di spazio disponibile. Ad esempio, vogliamo che /miopool/prova possa contenere, al massimo, 100GiB di dati:
zfs create miopool/prova zfs set quota=100G miopool/prova
Adaptive Replacement Cache e L2ARC
Nel precedente articolo vi ho parlato di ZIL. In questa sezione, invece, analizzerò le cache di lettura utilizzate da ZFS. Questo file system, infatti, non utilizza il classico algoritmo LRU, bensì una versione custom dell’algoritmo ARC creato dalla IBM. È possibile anche implementare una cache di lettura di secondo livello, denominata L2ARC. Questa è una “estensione fisica” della ARC, da impostare su un dispositivo di archiviazione veloce. Il suo utilizzo non è, in ogni caso, obbligatorio, ma può aiutare nelle operazioni di lettura e duplicazione. L’architettura complessiva sarà come la seguente:
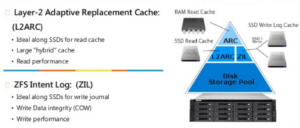
Come vi ho già spiegato nella parte 1, il vdev dedicato alla cache di secondo livello, deve essere di tipo cache. Anche in questo caso, l’istruzione da eseguire è semplicissima:
zpool add miopool cache Z
Snapshot
ZFS consente nativamente di creare snapshot istantaneamente, senza occupare spazio nel pool. Questo grazie all’utilizzo del COW. Il vecchio blocco da modificare, infatti, non è stato sovrascritto. Anche se è stato contrassegnato come libero dal filesystem, infatti, potrebbe volerci molto tempo prima che venga riscritto.
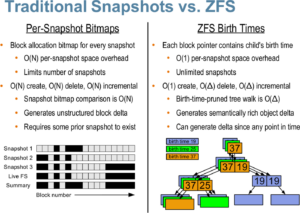
Per creare un’istantanea del dataset prova, presente nello zpool, l’istruzione da utilizzare sarà:
zfs snapshot miopool/prova@sunday
Per visualizzare la lista di tutte le istantanee, invece, bisogna utilizzare questa direttiva:
zfs list -t snapshot miopool
Per effettuare un rollback ad una precedente istantanea:
zfs rollback miopool/prova@friday
Siamo giunti alla conclusione di questa panoramica introduttiva su ZFS. Ovviamente ci sono ancora moltissime funzionalità che, per motivi di sintesi, non sono state trattate. Per chi volesse approfondire l’argomento la fonte migliore possibile è la documentazione ufficiale rilasciata da Oracle.
Che ne pensate di ZFS? Esistono file system migliori ? Ditemi cosa ne pensate qui sotto, nella sezione dedicata ai commenti!
 Seguiteci sul nostro canale Telegram, sulla nostra pagina Facebook e su Google News. Nel campo qui sotto è possibile commentare e creare spunti di discussione inerenti le tematiche trattate sul blog.
Seguiteci sul nostro canale Telegram, sulla nostra pagina Facebook e su Google News. Nel campo qui sotto è possibile commentare e creare spunti di discussione inerenti le tematiche trattate sul blog.
